编译原理 笔记 5
运行时存储组织
运行时存储组织的作用与任务是,在代码生成前安排目标机存储资源的使用,主要问题有:
- 数据表示:如何表示基本类型、指针、数组、结构体、对象等数据
- 表达式计算:在栈上计算还是在其他地方(一些机器会有运算栈)
- 存储分配策略
- 过程(函数)实现
程序运行时存储空间的布局
会根据机器的不同而不同,典型的一种布局为(从高地址开始):
- 保留区
- 栈(地址往低扩展)
- 堆(地址往高扩展)
- 共享库和分别编译模块
- 静态数据区
- 代码区
- 保留区
存储分配策略
- 静态存储分配:在编译期就确定要分配的空间,但是适用范围很小
- 栈式存储分配:有效实现可动态嵌套的程序结构,我们将运行栈中的数据单元称为活动记录
- 堆式存储记录:从堆空间为数据对象分配或释放存储,分为显式和隐式两种
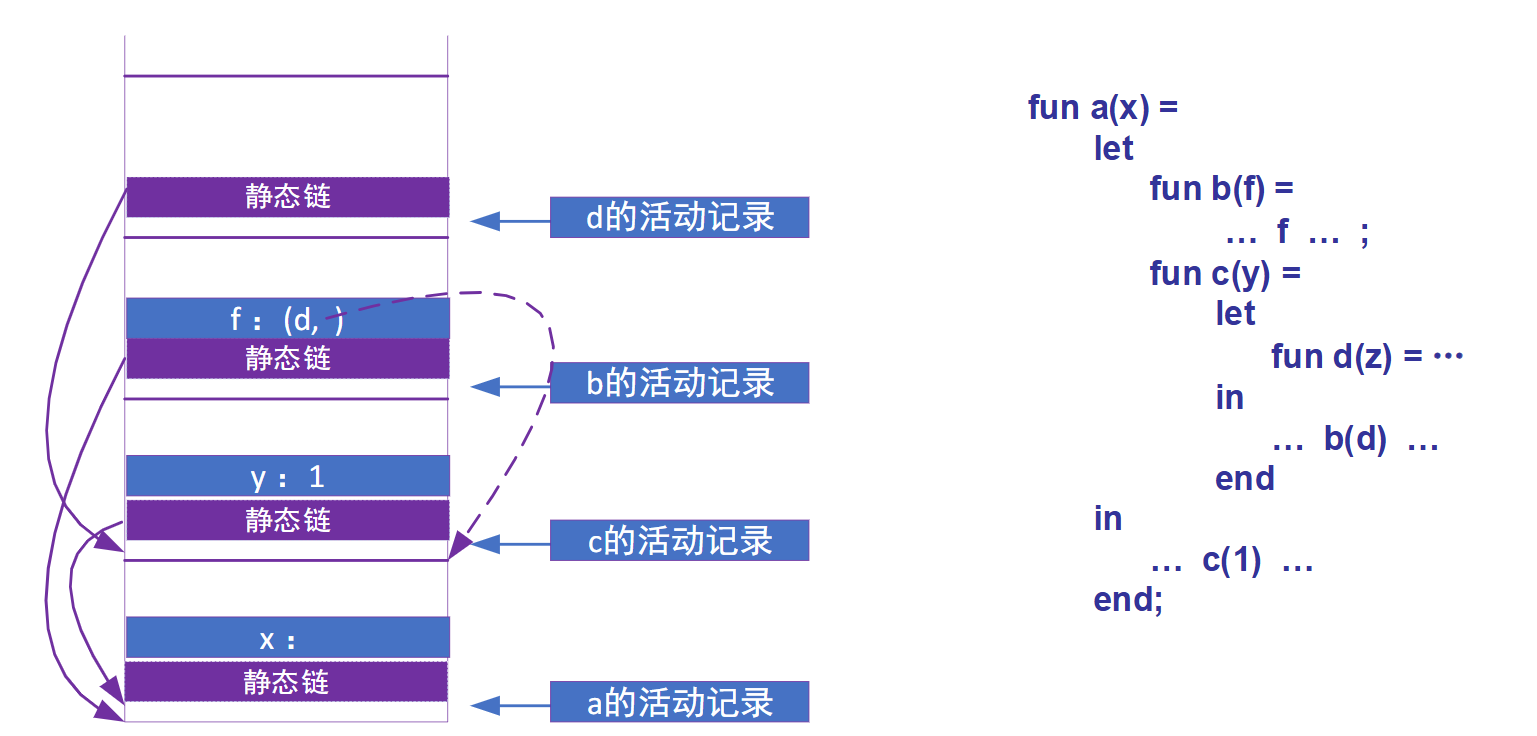
活动记录
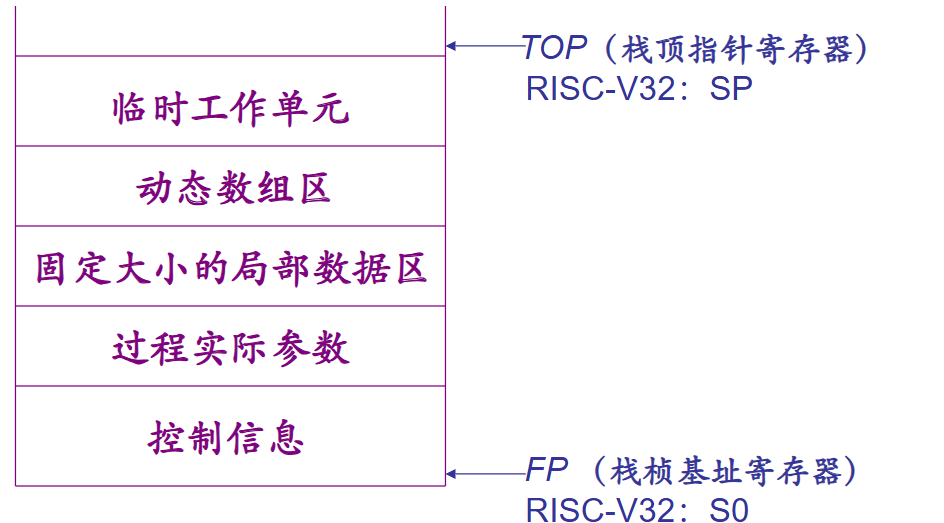
即栈帧,栈帧基址位于 fp中,栈顶指针位于sp中
动态链与静态链
对于嵌套定义的函数,例如下面这段:
1 | def P(): |
我们需要使用动态链和静态链来帮助内层函数访问非局部数据:
- 动态链:指向调用此函数前最新的栈帧基地址
- 静态链:指向此函数直接外层函数最新栈帧的基地址,如果是全局函数则指向0
例如在前面的函数中,调用P()之后的栈帧显然是PQRPQR,此时R的DL会指向其caller,也就是其前一个Q,而SL会指向定义R的函数的最新栈帧,在这个例子里面同样是前一个Q
Display表
Display表是一个K+1维的数组,其中K是当前嵌套层数,D[i]代表当前函数、直接外层、……、最外层这条嵌套定义链条上每一个函数的栈帧基地址
Display表可以直接存储在栈帧中,这样每次调用或恢复函数的时候只需要从caller或callee的栈帧中读取Display表并作处理即可
但是这会导致栈帧过大,因此我们采用增量法:也即利用每次调用或恢复嵌套函数其实只会影响表中特定一项,在全局记录一个Display表,每次调用函数对表的影响(被移除的表项)记录在callee的栈帧中,恢复时根据callee的嵌套深度对相应的表项进行恢复
动态/静态作用域
动态作用域与静态作用域(很抽象)实际上和实现方式强相关,也即在全局和局部重复出现的重名变量,应该如何处理
考虑这段代码:
1 | var x |
如果是静态作用域,也即show函数中x的地址应该为为全局x的地址,也即从show函数开始,在作用域栈中寻找,因此输出的结果应该为:
1 | 2 2 |
但是如果是动态处理,则在showSmall中调用show时,其中的x应该为在showSmall函数中定义的局部变量,也即从这一次调用的show函数开始,在函数调用栈中寻找,也即因此输出的结果应该为:
1 | 2 1 |
在JavaScript V8 13.1.201.9中,这段代码运行的结果为
2, 2
静态和动态的定义为:
- 静态:从函数开始,在作用域栈中寻找
- 动态:从函数调用开始,在函数调用栈中寻找
函数参数传递
两种方式:
- call-by-value
- call-by-reference
如果允许嵌套函数,则会出现将外层函数局部变量作为函数参数的过程,这是一个较为复杂的过程,一种解决方法是在存储函数实参的时候添加SL,如下图: