DLRM 总结
DLRM
AdaEmbed
- 提出了In-training pruning system AdaEmbed,动态优化embedding table
- 应用了VHDI
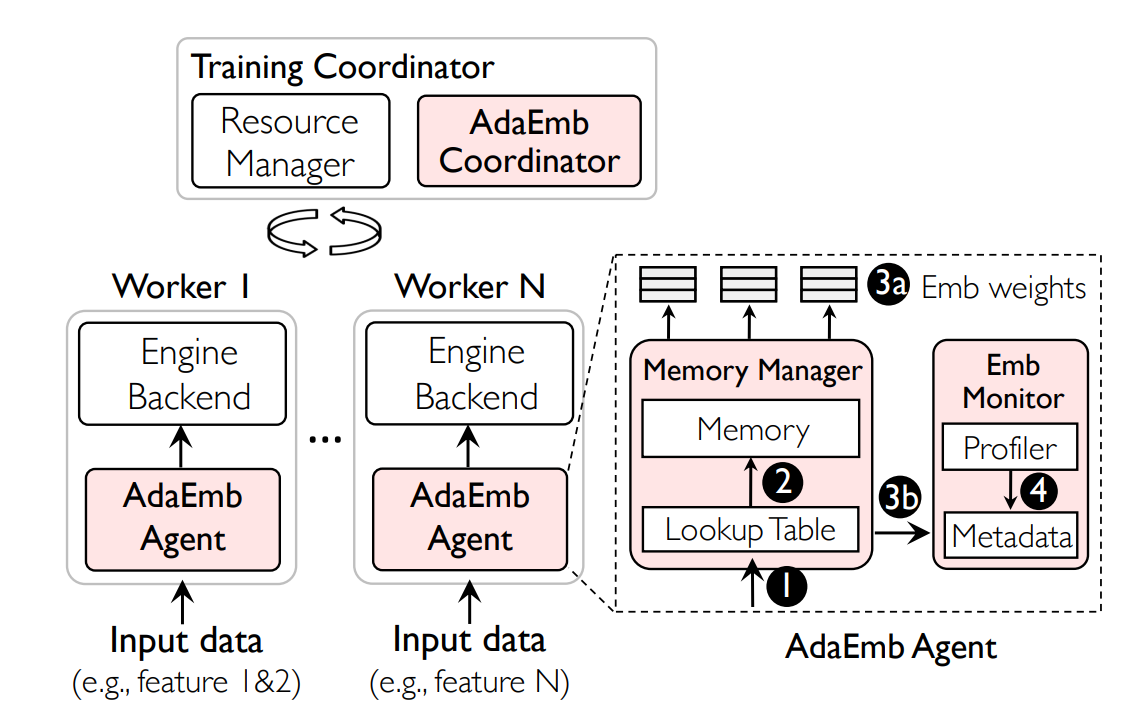
具体算法为:

包含了三个主要模块:
- AdaEmbed Coordinator: 从Agents处收集importance,决定prune strategy,协调prune的执行
- Memory Manager:每一个Agent会内置一个,用于管理Embedding table的物理内存
- Embedding Monitor:决定importance,向Coordinator通信
同一个table内,每一个embedding row会有一个来决定其重要性,更新方法为:
并且每次迭代进行一定比例的衰减
不同table之间,首先对每个table的importance,利用这个特征的分布的下95%分位数做归一化,之后将embedding vector dim相同的feature划分成一个group,在group内做prune,每个组结果的embedding table大小由总大小按比例分配得到
决定prune的时机需要判断embedding vectors中importance变化足够剧烈的有多少,但是全部判断overhead太大,因此在每一个agent中sample一小部分出来判断,并据此估计全局
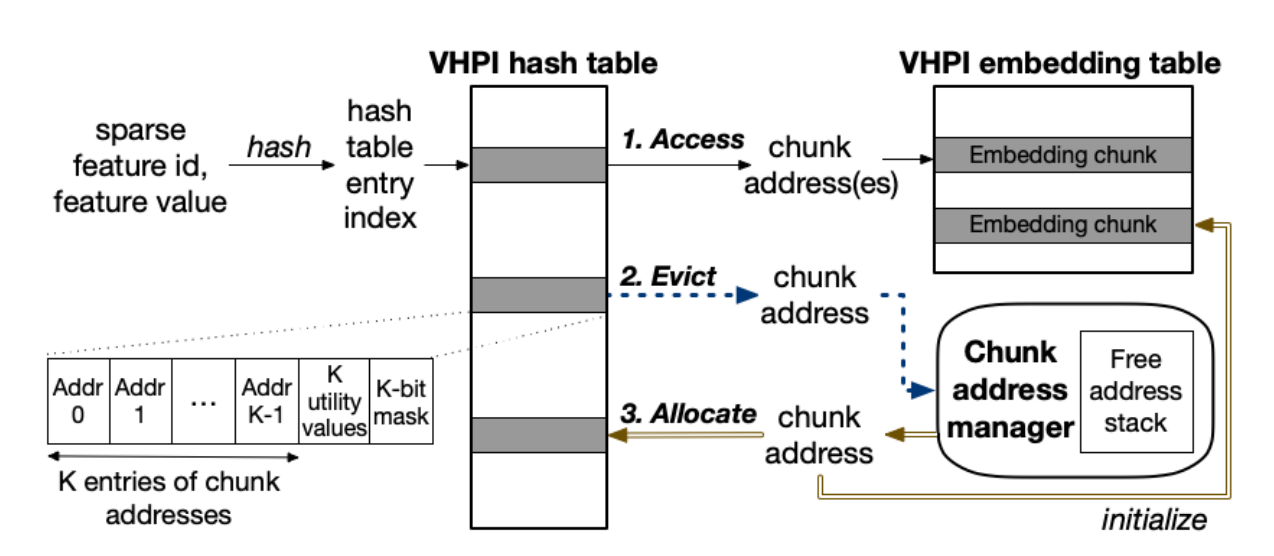
为了避免过多的内存开销,引入VHDI(感觉很像页表)
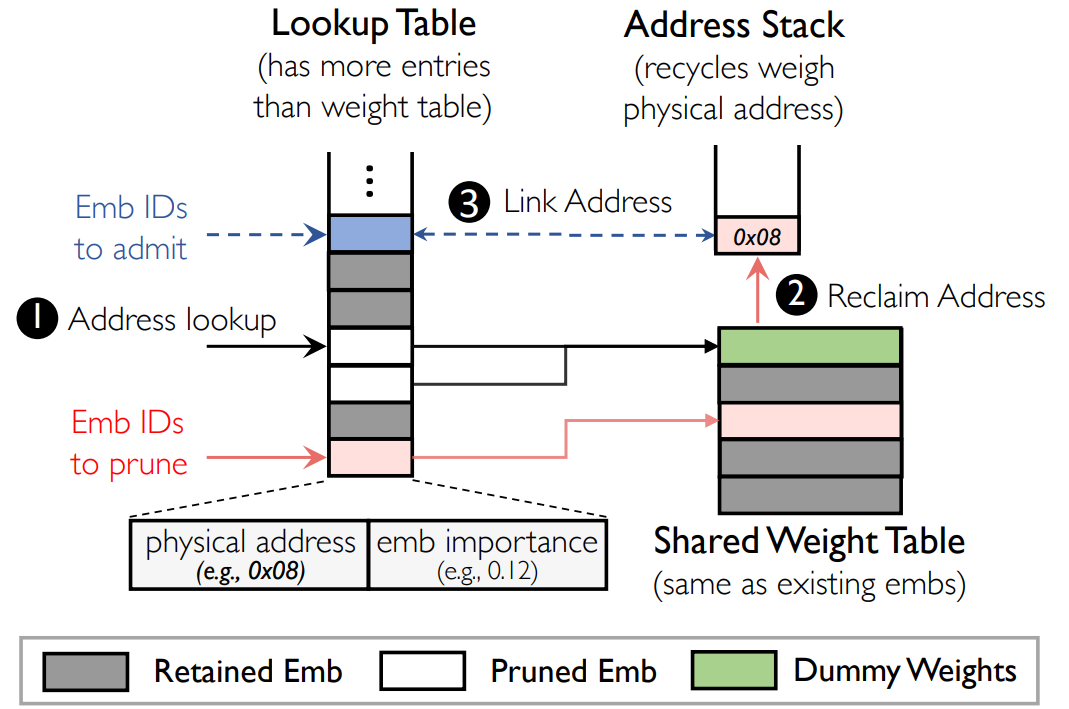
重分配一个embedding的时候直接zero-initialization
FIITED
基于以下观察:
- 不同特征之间的重要性不同
- 每个特征对应嵌入表中,行的重要性不同
- 每一个嵌入向量的维度重要性不同
- 重要性会随着时间发生改变
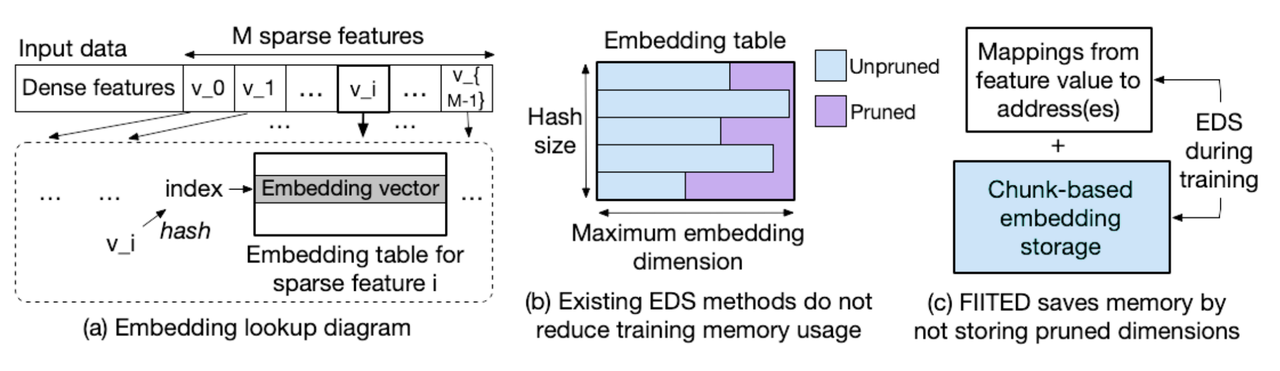
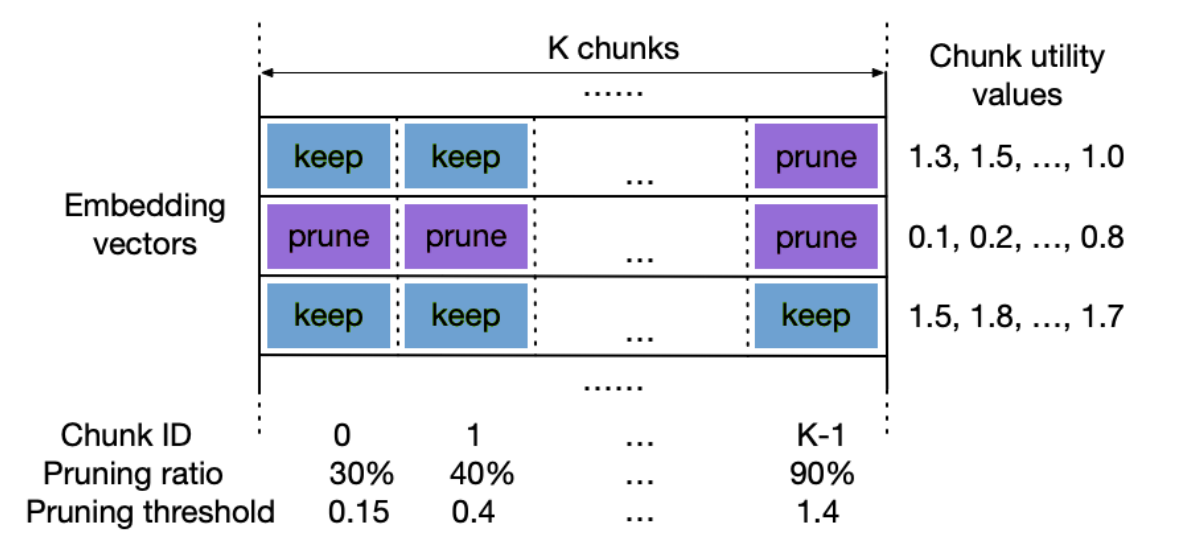
将嵌入表中的每一个嵌入向量分成了多个chunk,嵌入表的store与prune是基于chunk进行的,减少了内存使用
当一个prune了的chunk需要重新keep的时候,其值会被重新初始化
在做训练的过程中,对于不等长的embedding vector,采用zero-padding的方式
每次迭代的过程中,更新chunk utility value的方法是:
其中是访问次数,是梯度的2-范数
chunk的pruning ratio可以指定也可以训
同时也可以prune某一些dimension,相当于将不同embedding tables的同一个维度当成一个样本,决定其importance并决定是否prune
如果直接实现这个算法,会导致有大量的内存碎块,因此使用AdmEmbed中提出的VHDI算法,并添加一个chunk manager
优化了四个方面的开销:
- hash表查找
- Embedding table查找
- 更新每一个chunk的utility value
- Prune
方法是:
- 并行计算每一个chunk的utility value与并行prune
- 将前一个batch的utility value update放在后一个batch的forward过程中并行完成
- 采用pre-fetching技术优化两次查表