DistriFusion & PipeFusion 相关内容
多卡并行的两种方式
DistriFusion
针对U-Net架构的Diffusion Model进行改进
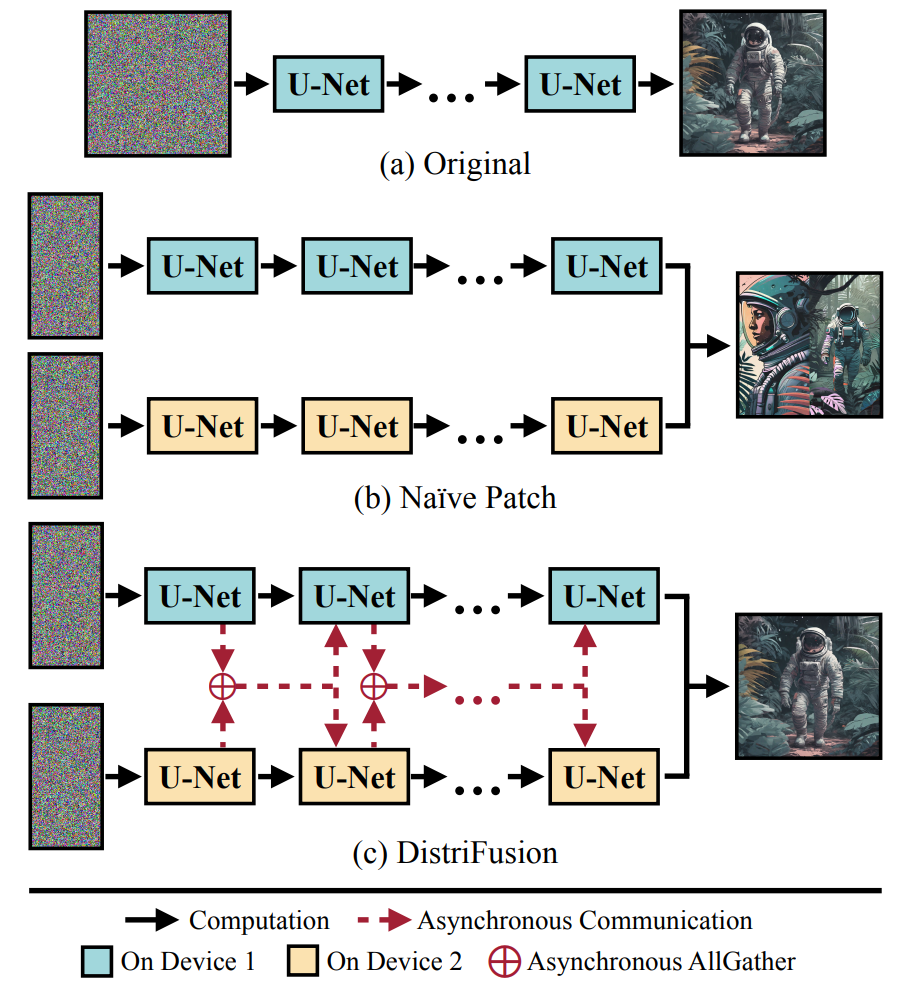
传统diffusion缺少多卡并行能力,如果直接将image切分的话,缺少通信的patch产生的图片会不合预期,而使用同步通信则会导致通信时间过长,消除了并行的优势
考虑到diffusion中相近step之间输入具有近似的特点,于是做异步通信:
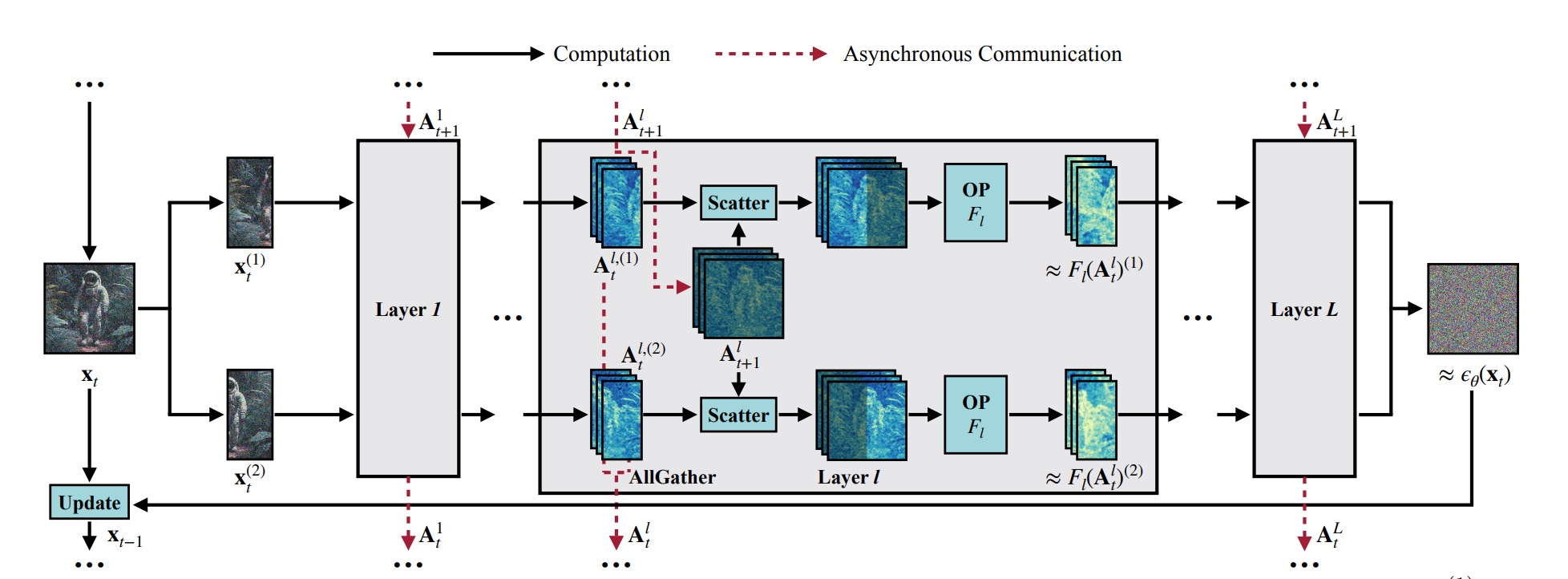
第步第层会有记录此时的完整输入,在切分到个设备上后,每个设备仅有这样一部分的输入,此时会异步传到这里(通过AllGather),并做一次scatter分配到每台设备上,使得每台设备只需要自己提供的输入即可,其他的输入都复用上一步的
由于Scatter的结果中只有是新的,因此可以修改使其支持稀疏操作:
- 如果是卷积或线性层等,则直接将新的一部分作为输入即可
- 如果是Self-Attention,则将其换为Cross-Attention,即使用新图片的与全图片的作Attention
然而这一步通信$KV$可能导致内存开销过大
但是U-Net需要进行GN,而不完整的图片无法计算GN,新算法:
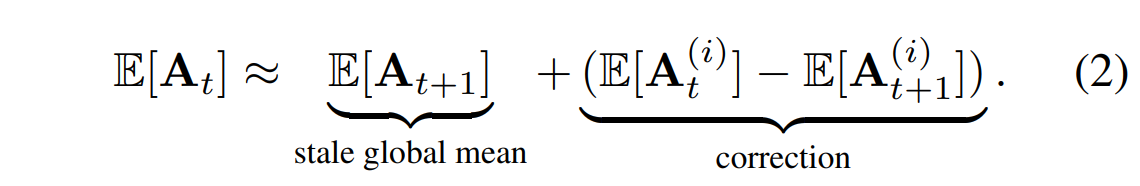
也即在每台设备上用局部信息来更新并估计全局,并分别作GN,之后通过异步通信将每台设备上的信息整合起来,计算精确的全局信息
最后,在实验的时候,并没有一开始就使用DistriFusion,因为初始的一些步骤主要是构建整体布局和全局语义,随着采样的进行,每一步主要变成了复原局部细节。因此采用了预热步骤,也即先使用了若干轮的传统同步通信
PipeFusion
针对DiT进行改进
DistriFusion有一些不足:
- 应用于DiT时,需要在每台设备之间对于每一层的矩阵均进行通信,导致通信缓存巨大,造成内存浪费
- 对带宽要求高,需要将每一层的完整中间激活都在timestep之间进行传递
于是提出了新的方法PipeFusion
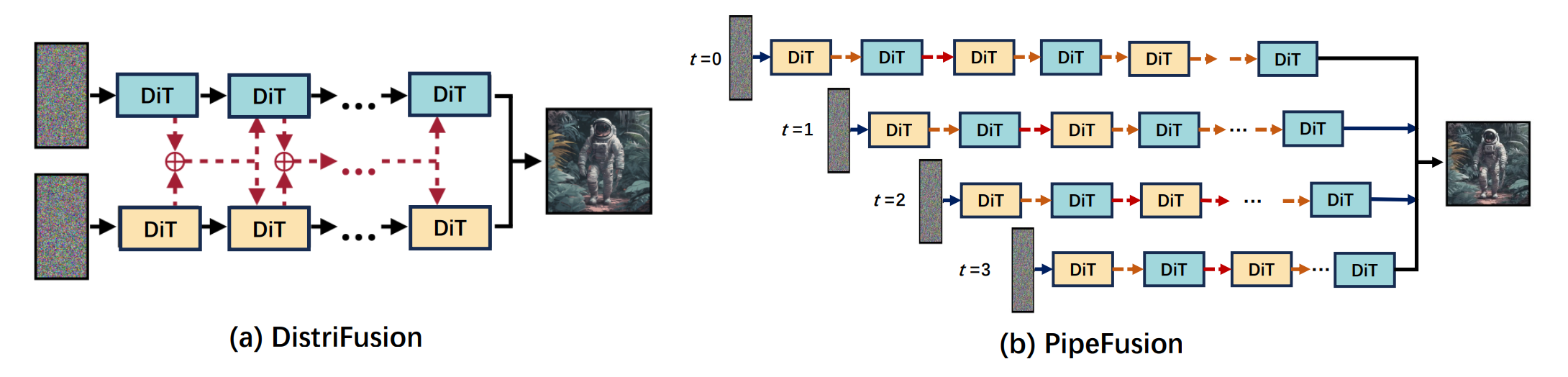
PipeFusion也利用了DistriFusion中观察到的现象,并将其命名为输入临时冗余
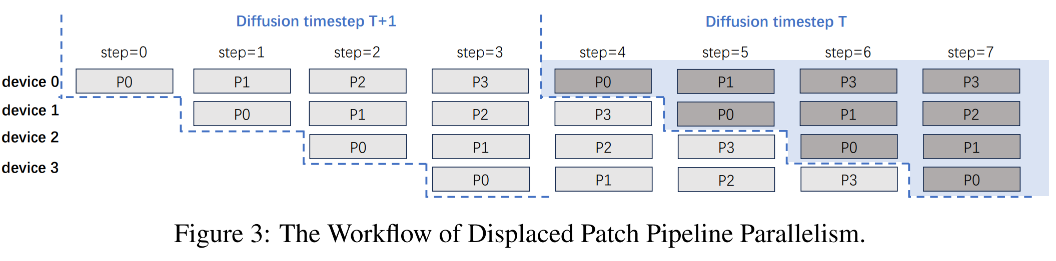
图中,Transformer中的层被划分到台设备上,每台设备只负责其中部分的计算,也即每台设备只需要保存自己负责的层所对应的矩阵即可,避免了这一步带来的通信开销和内存开销
其中每一台设备上有一个buffer用来存储激活,当处理前面的patch时,由于一个device会随着流水线的流动逐步处理所有的patch,因此buffer中是存储每一个patch对应的activation,当计算完成一个patch的时候就将其对应的activation更新,使得其相比DistriFusion来说应用了更多的fresh activation

DistriFusion中的新GN算法、预热步骤等都可以应用到PipeFusion中,但是有一些修改:
- DiT不需要GN
- 将预热步骤分配在其他计算资源上,减少其开销