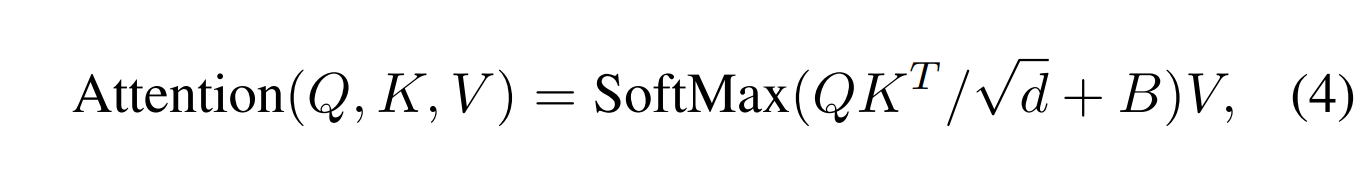Swin Transformer
一种基于移位窗口的层次化Transformer
基本架构
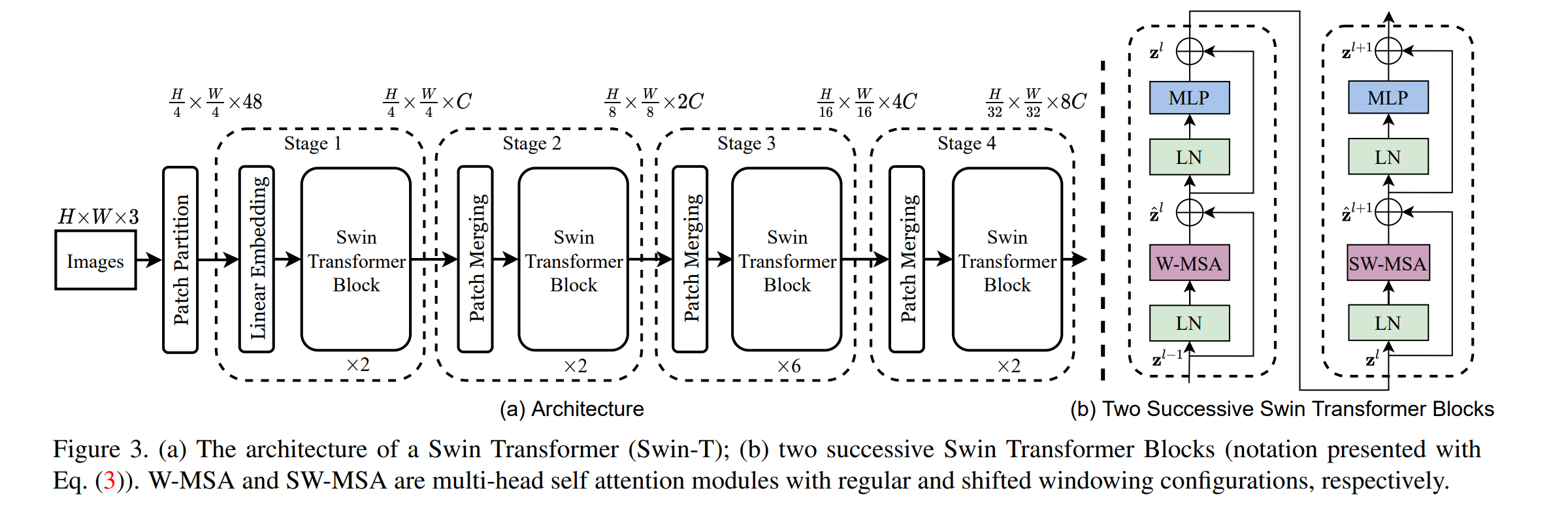
首先将输入的RGB图片划分为不重叠的patch(图中大小为443),之后将每一个patch扁平化位移位向量,这样初始化图像转化成了,之后将patch进一个MLP将其维度变为
之后进行patch的合并,每次将2*2单位内的patch进行合并,之后进一个MLP保证patch的大小只扩张两倍
这种架构可以方便的替换其他一些网络中的backbone
而Swin Transformer块是将传统的Multi-head Self Attention替换成了(Shift-)Window MSA,每一Stage中的层数可能不同,由超参数决定
(S)W-MSA
用于解决常规Attention平方复杂度的问题,将图片划分为不重叠的窗口,窗口的大小为,而其中为常数,这样可以将计算的复杂度从降到,但是这样的话失去了窗口之间的联系,可能导致信息的丢失,于是引入窗口的移位,即SW-MSA
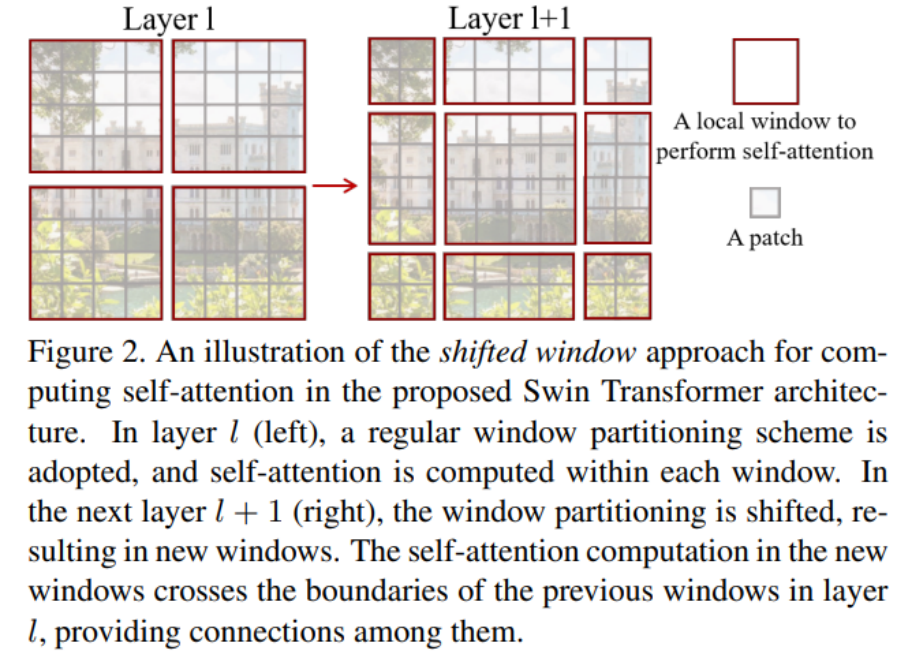
第l个模块是W-MSA的话,第l+1个就会是SW-MSA,会将窗口向左上循环移动位,确保了跨窗口信息可以被保留下来
但是如果按照Fig2中的移动方式,窗口数会从变成,因此采用下面这种方式:

这种方式不会增加窗口数量,但是每一个窗口可能是由许多子窗口拼接而成的,因此引入masked限制attention的计算范围,也即给每一个窗口一个index,在attention的过程中只留下相同id窗口的计算结果,忽略其他值,这一步需要依靠根据当前窗口的排布来确定mask
在计算attention的过程中,引入相对偏移矩阵:

其中,因此,其是从中取值得到的
的每一行分别代表了以窗口的第个patch为原点时,其他patch针对原点的相对偏移量,并通过偏移数组来确定偏移量,详细计算过程参考博客
原版参数设置