Diffusion Transformer相关
LDM简介
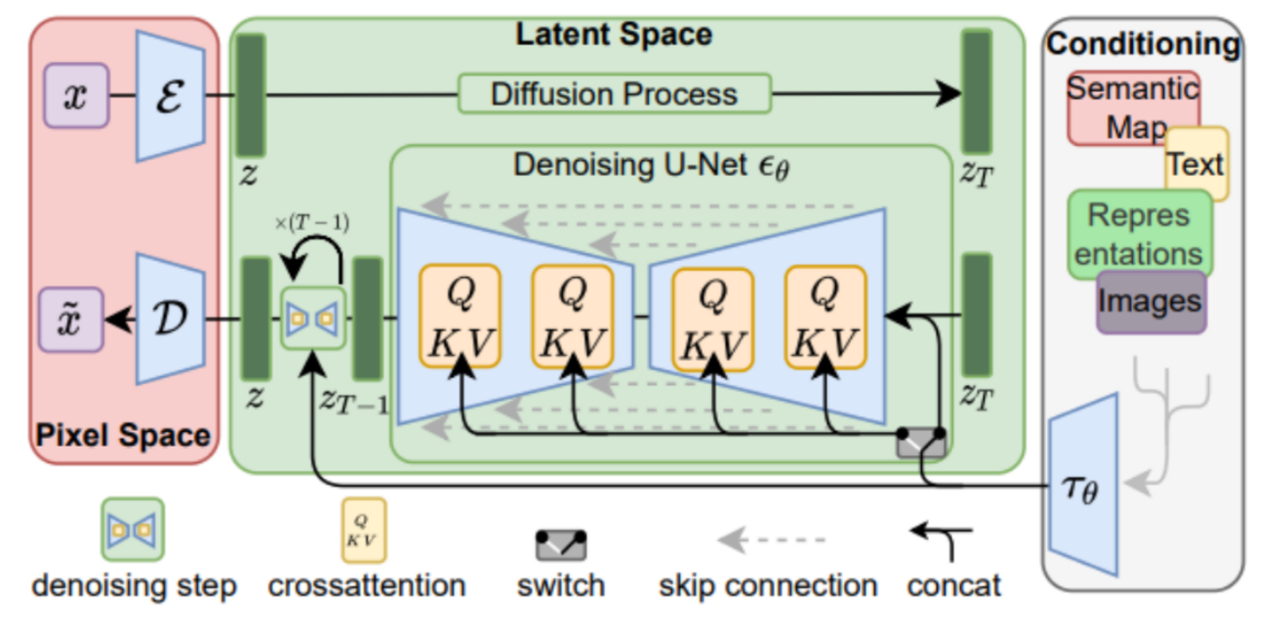
架构如上,代表编码器,负责将像素空间的输入映射到潜在空间,代表解码器,负责将潜在空间的输出映射到像素空间,中间利用U-Net进行去噪,同时是Condition编码后的参数,通过CrossAttention与潜在变量结合起来
DiT
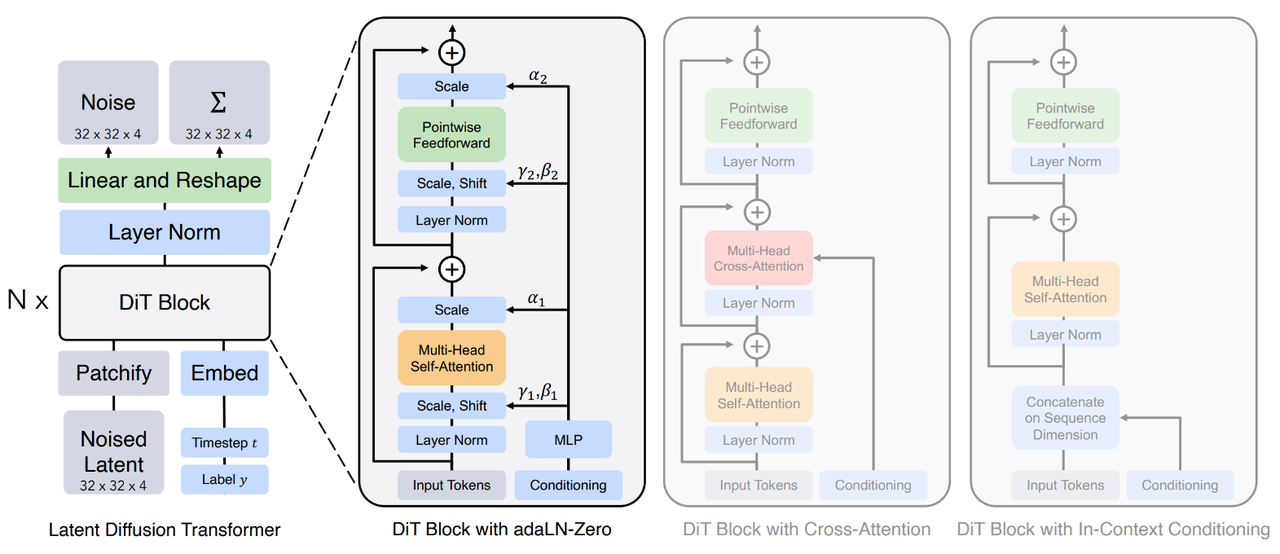
基于LDM的一个模型,将其中原本用于Denoise的U-Net修改为Transfomer架构,称为DiT Block,而VAE则是由已有的部分:
Patchify
对输入的latent noise做扁平化:
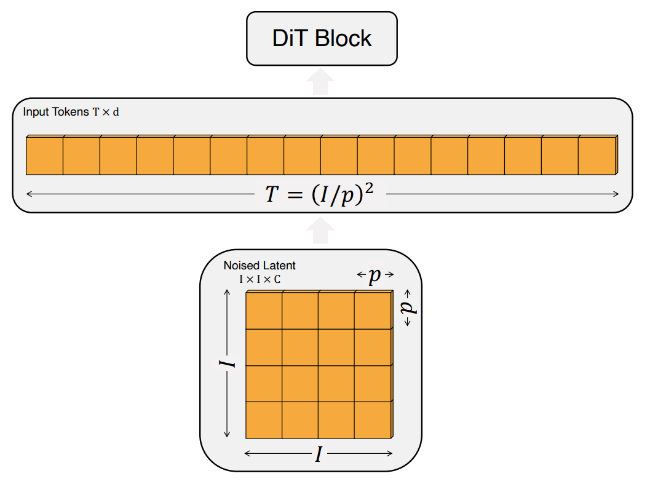
将图像切分成多个大小为 的补丁,然后将其转换为长度为 的序列作为 Transformer 的输入。这使得 DiT 能够处理不同分辨率、持续时间和长宽比的视频和图像。
其中的大小会影响GFLOP,减半GFLOP乘4,但是对下游参数数量没有影响。
DiT Block
按照对条件信息的处理方式分为三种:
In-Context Conditioning
直接把Condition和Image拼接在一起,最终一次迭代不拼接,对GFLOP影响很小
Cross Attention
Image做一次Self-Attention之后,再和Condition做一次Cross Attention,会提升15%左右的GFLOP,这个和LDM中使用的方法是很相似的
Adaptive Layer Norm(adaLN)
传统的LayerNorm,在做完归一化之后的线性映射参数是直接训练得到,与输入无关,和adaLN中线性映射的采纳数是输入经过一次MLP部分得到
用Adaptive Layer Norm替换Transfomer中的Layer Norm部分,并且这其中的参数与Image无关得到,而通过Condition经过MLP之后得到,对GFLOP影响最小
adaLN-Zero
先把输出都初始化为0,这样每一个残差块的初始输出都为恒等映射,训练成本更低
Decoder
用一个线性decoder来做解码,输出一个噪声预测与一个对角协方差预测