人智导 对抗搜索
对抗搜索
对于一些分支极多的对抗式问题,穷举法所需要消耗的时间、空间资源无法承受,无法实现,因此考虑充分的剪枝
极小-极大模型
进行有限步内的穷举,从根节点出发,叶节点标记得分,并且期望每位选手都选择对于自己最有利的走法,最后选择期望得分最高的一步
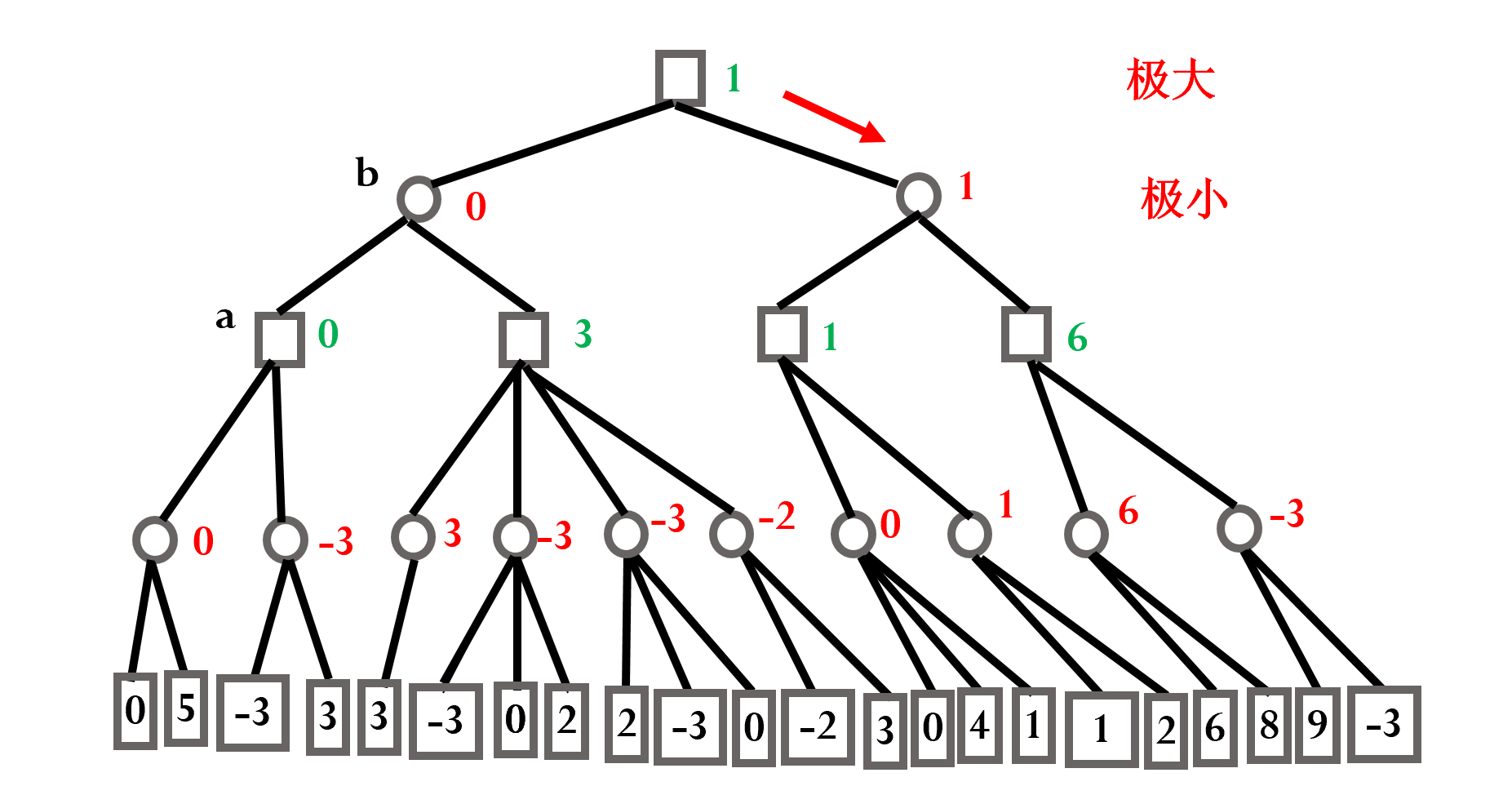
图中,两种图形代表两位选手,分别记为,叶节点上所标记的为在四步之后的期望得分,每位选手每步都是期望自身得分尽量高(对方得分尽量低)
但是极小极大仍然没有剪枝,时空资源仍然无法承受
α-β剪枝算法
- 剪枝算法如下
为极大节点(我方选手尽量多得分)的下界
为极小节点(我方选手尽量少得分)的上界
后辈 祖先 时, 剪枝
后辈 祖先 时, 剪枝
实例如下:注意比较时需要和祖先节点而不是父节点比较
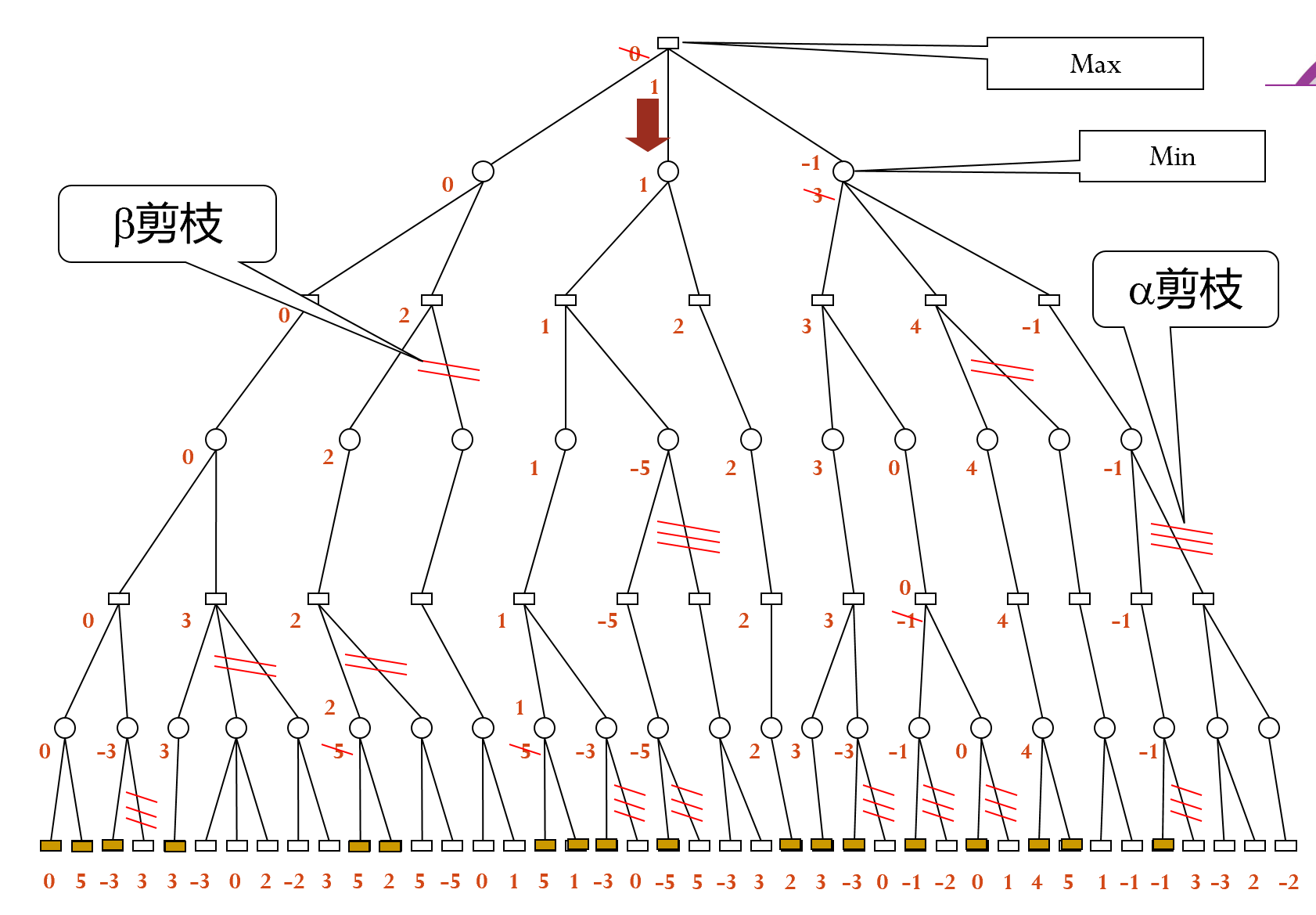
每次- 剪枝只能得到下一步的走法
局限性:非常依赖局面估计(也就是叶节点的得分)的准确性,需要大量的专家知识与人工整理
蒙特卡洛(MCTS)
基本思想:
- 可能出现的状态用状态树表示
- 逐步扩展树节点
- 父节点利用子节点的结果
- 随时得到行为评价
基本过程为:
选择 扩展 模拟 回传
选择策略
考虑两方面因素:
- 充分探索尚未探索的节点
- 利用效果尽量好的节点
因此采用多臂老虎机模型
拥有个拉杆的老虎机,拉动每个拉杆的收益相互独立并且遵循一定分布,求如何使得受益最大化
采用信心上限算法:每次选择信心上限最大的节点,节点的信心上限计算方式为:
其中参数含义为:
- :调节参数
- :访问次数
- :此时节点 被访问的次数
- :此时节点 的平均收益
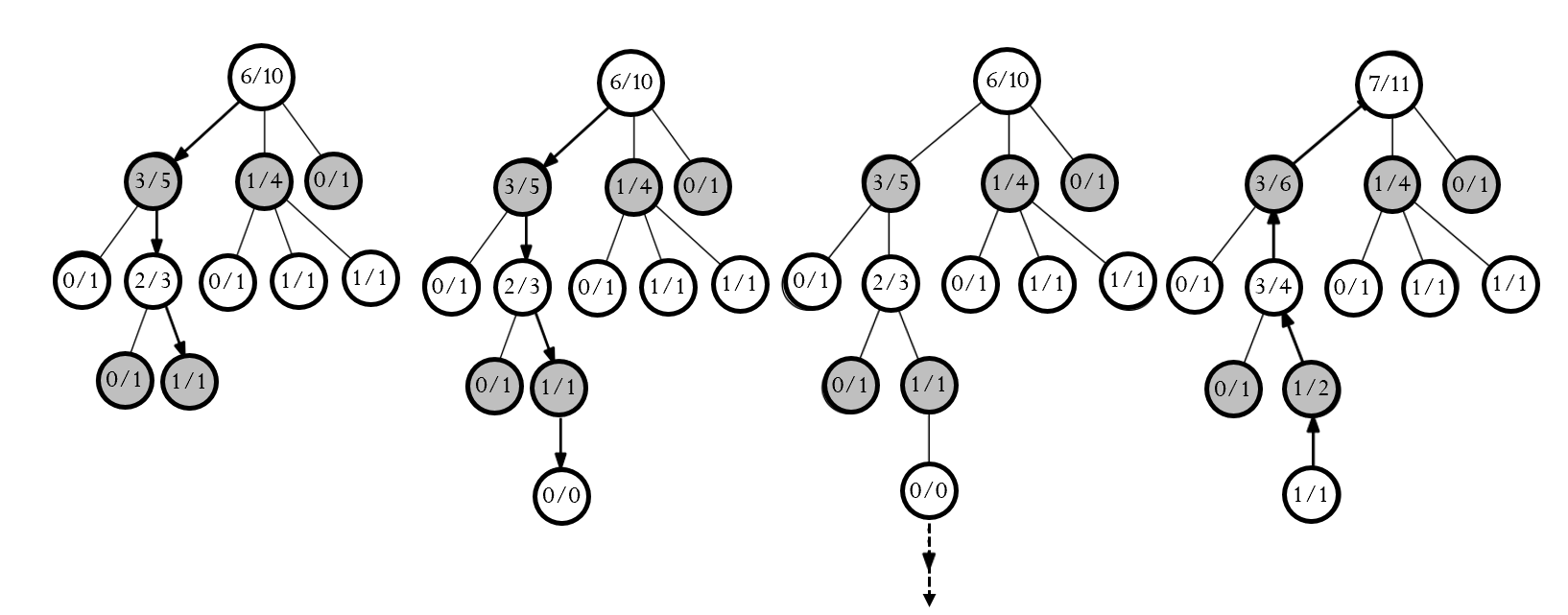
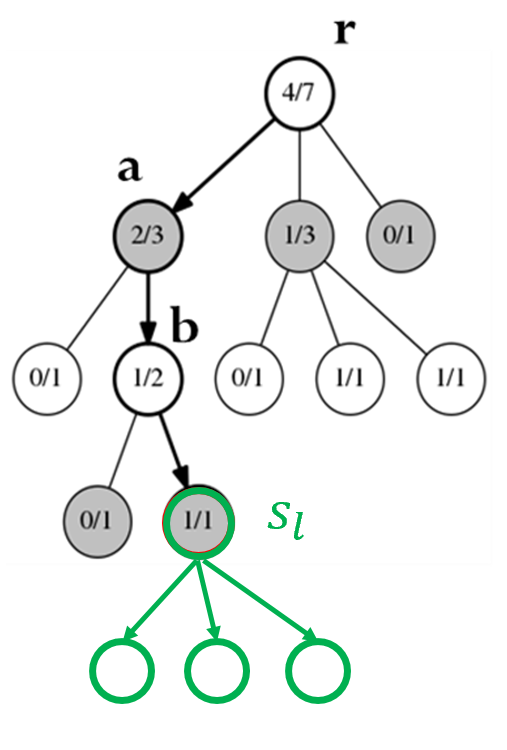
以围棋为例,每一次模拟可以看成是随机落点,平均收益可以看成是胜率,如下图,其中为简便令,最终选择根节点的子节点中胜率最大的节点作为下一步:
注意:
每个节点的胜率是站在己方的角度考虑的!
AlphaGo
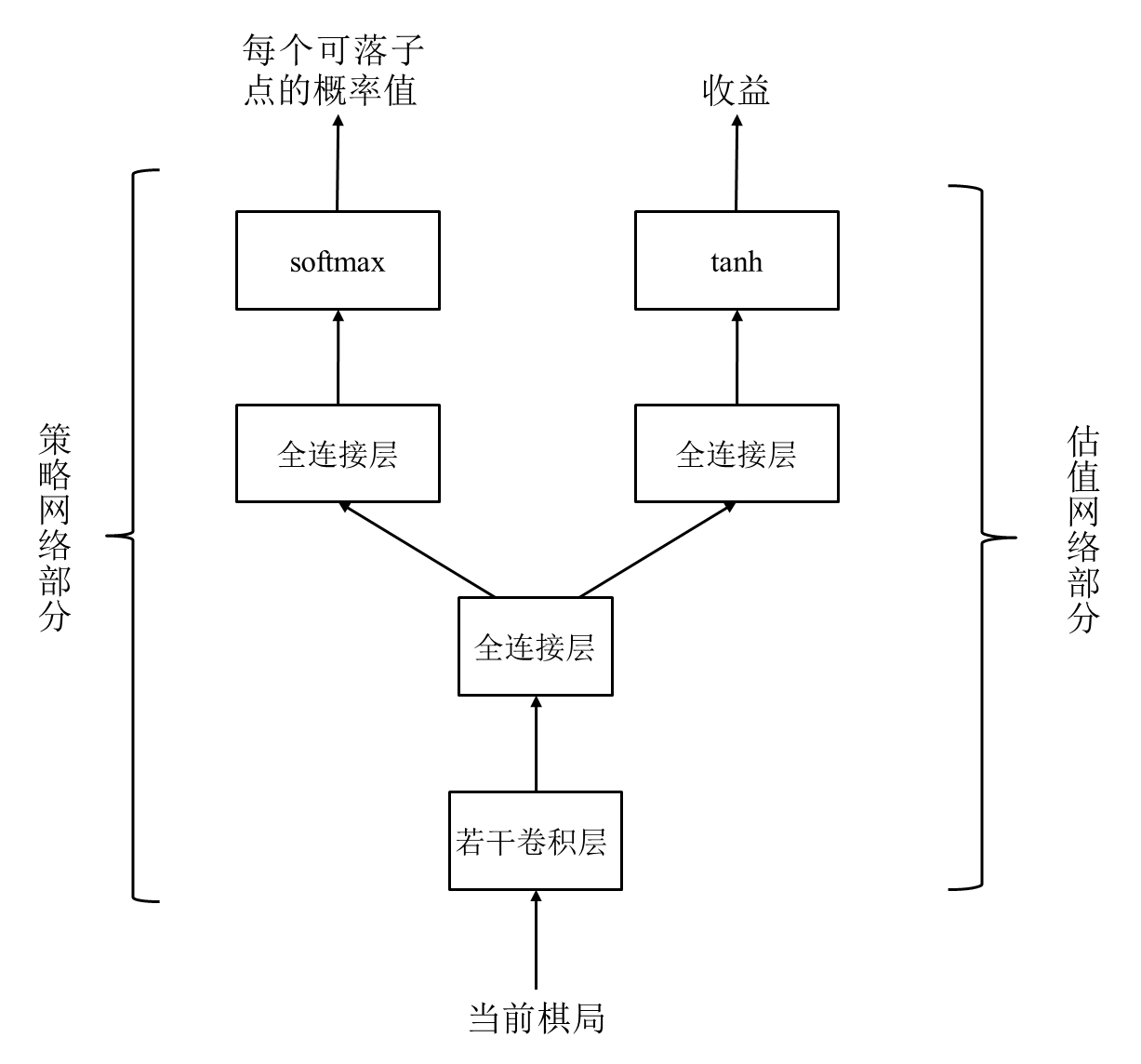
为了解决MCTS的盲目性问题(随机落子),将神经网络与蒙特卡洛结合起来,使用了策略网络与估值网络两种神经网络
策略网络
一个神经网络,用于提供行棋概率
输入:48个通道,每个通道大小19*19,记录了棋局的相关信息
输出:棋盘上每个节点的行棋概率
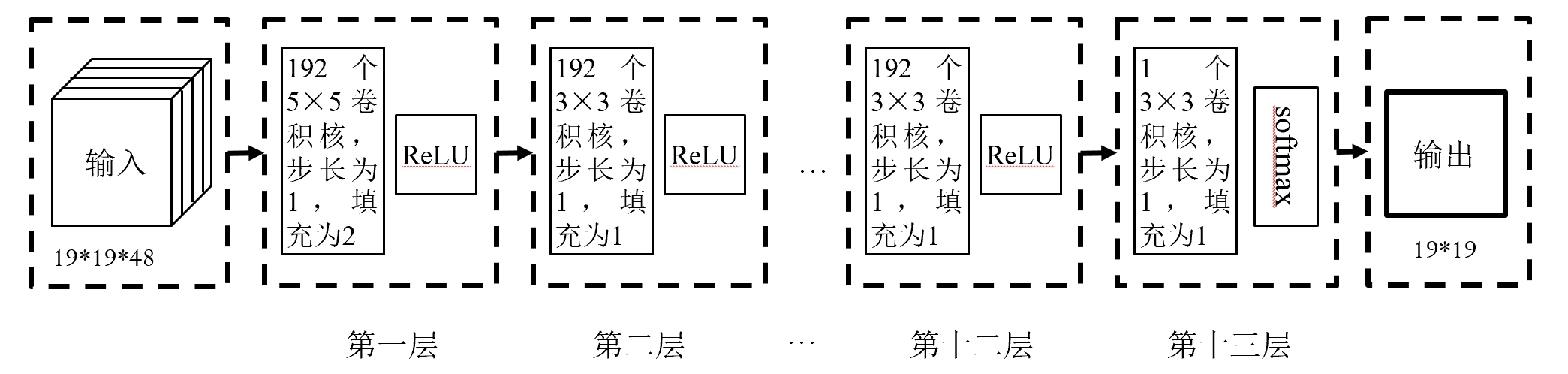
策略网络可以看成是一个361类别分类问题,通过人类棋手的棋谱进行训练,损失函数为
其中为实际落子概率,为网络落子概率
估值网络
一个神经网络,用于提供棋局收益
输入:49个通道,每个通道大小19*19,记录了棋局的相关信息(比策略网络多一个)
输出:当前棋局收益
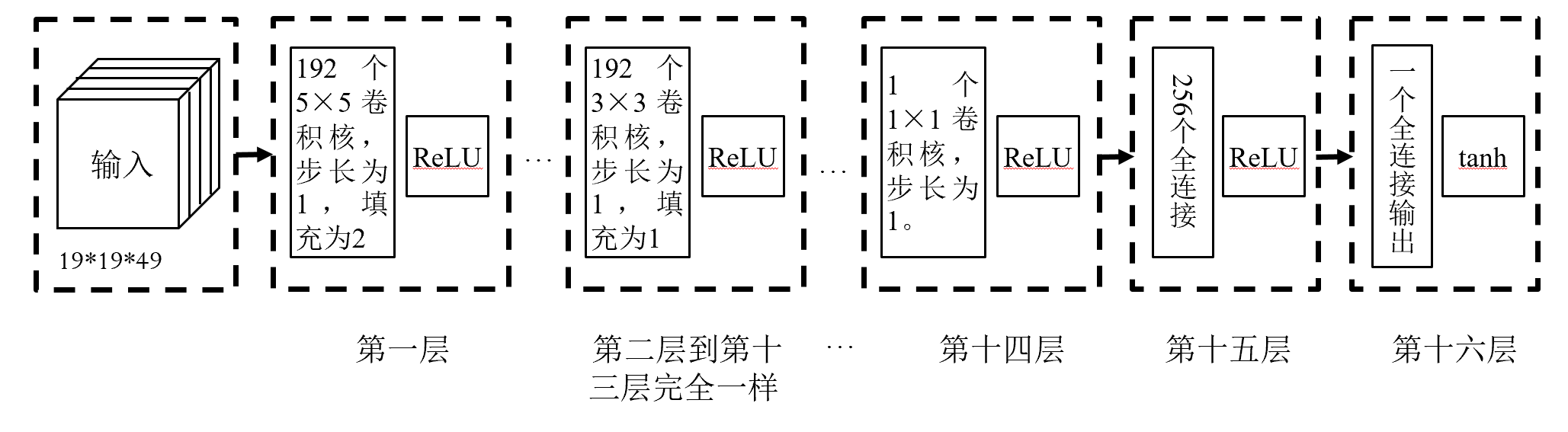
估值网络可以看成回归问题,也是通过人类棋手棋谱进行训练,损失函数:
其中为实际收益, 胜 负,为网络输出
与MCTS融合
给定参数
每次模拟收益为:
其中 为估值网络输出, 为模拟结果
因此定义平均收益:
定义探索项:
其中:
- 代表棋局在处落子后的棋局
- 代表对于棋局的模拟次数
- 代表策略网络对于的输出
- 为系数
信心上限切换为:
MCTS过程如下:
- 信息:每个节点记录收益、到达该节点概率与被选择次数
- 选择:从根节点开始,每次选择子节点中信心上限最大的节点,直到叶节点即停止并选中
- 生成:生成选中节点的所有叶节点(也即所有可能的落子),并规定了最大的节点深度
- 模拟:采用推演策略网络(更快),计算其
- 回传:注意正负号(即注意行棋是双方依次进行)
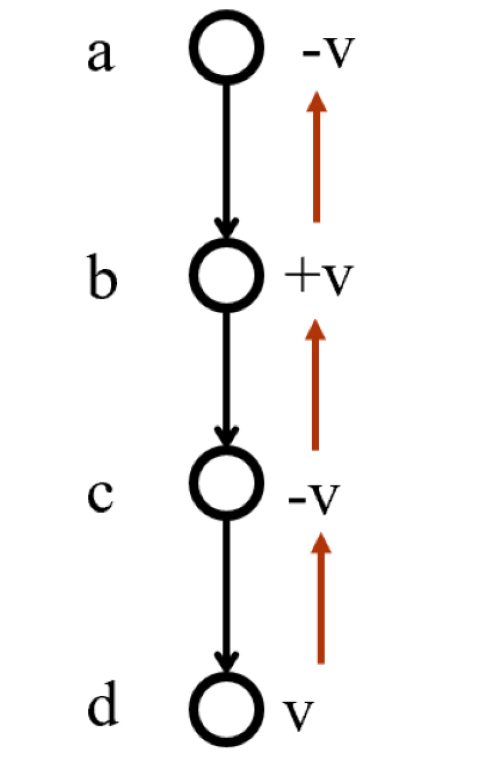
最终将根节点的子节点中,被选择次数最多的节点作为选择
深度强化学习方法
强化学习:学习“做什么可以使得收益最大化”
深度强化学习:利用深度学习实现的强化学习
以围棋为例,通过自己博弈训练策略网络,三种实现方法:
- 策略梯度:学习每个点获胜的概率
- 价值评估:学习每个点获得最大收益的概率
- 演员评价方法:学习到每个落子点获得最大收益增量的概率
策略梯度
数据由自我博弈产生,损失函数为:
其中,为当前棋局在处下棋的概率,为胜负值

注意点:
- 强化学习过程中,每个样本只使用一次
- 该方法学习到的是每个可落子点行棋的获胜概率
价值评估
输入为当前棋局和行棋点,输出为该行棋点的价值,在之间,数据也是自我博弈产生,损失函数为:
其中,为胜负值,为棋局在处落子后网络的输出
演员-评价方法
利用收益增量评价一步棋的好坏:
其中,为棋局的预期收益,为在处行棋之后的收益,在实际中常去为胜负值,最终越大收益越好
损失函数为:
AlphaGo Zreo
将估值网络和策略网络合并为“双输出”网络
输入:17个通道,记录8个棋局,每个棋局2通道,1个通道记录行棋方
输出:策略网络输出362维,增加的一维为放弃;估值网络输出棋局的估值
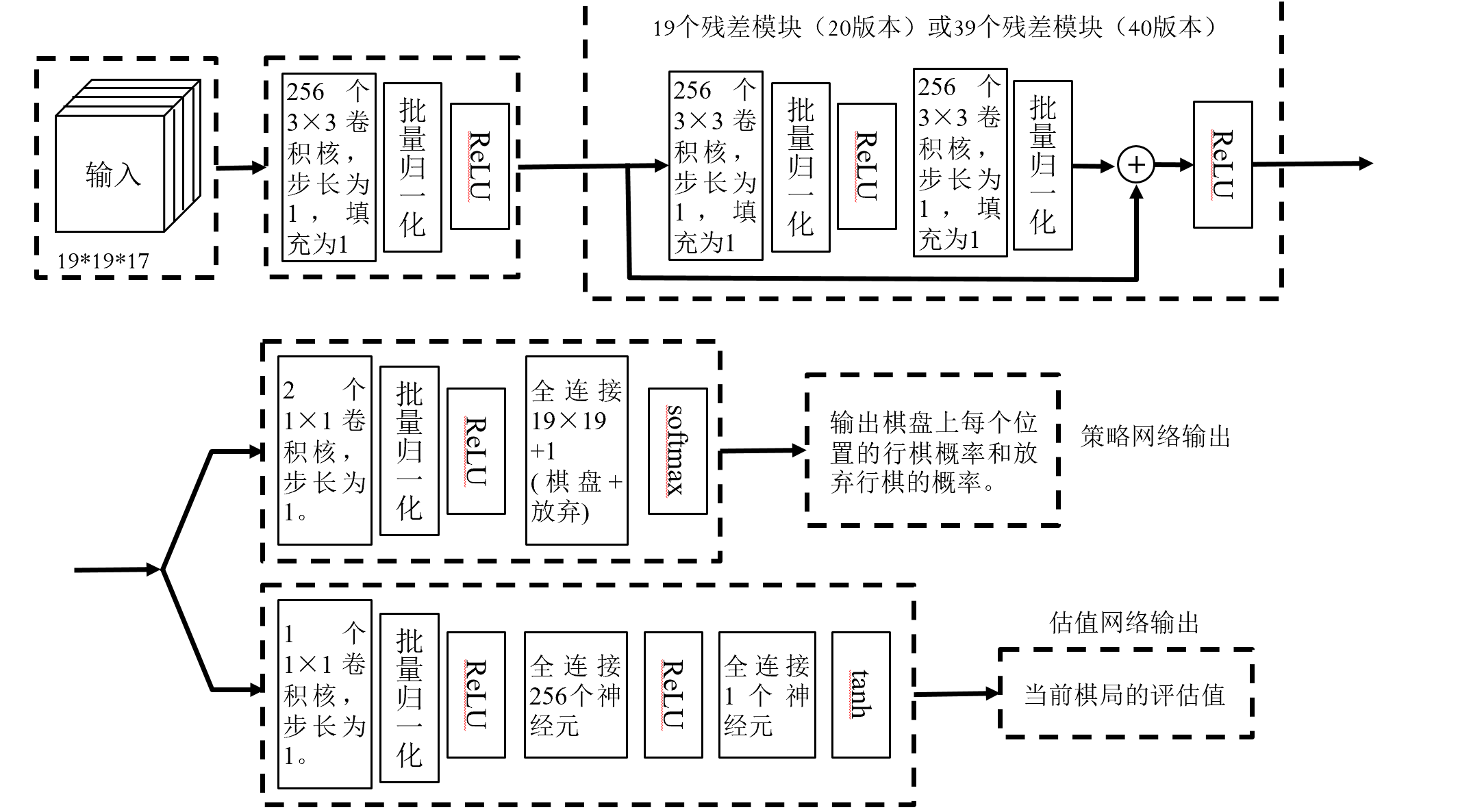
与MCTS融合
与AlphaGo基本相同,差别如下:
- 模拟被估值网络完全取代,模拟收益即为估值网络的输出
- 规定了总模拟次数
结合MCTS与深度强化学习
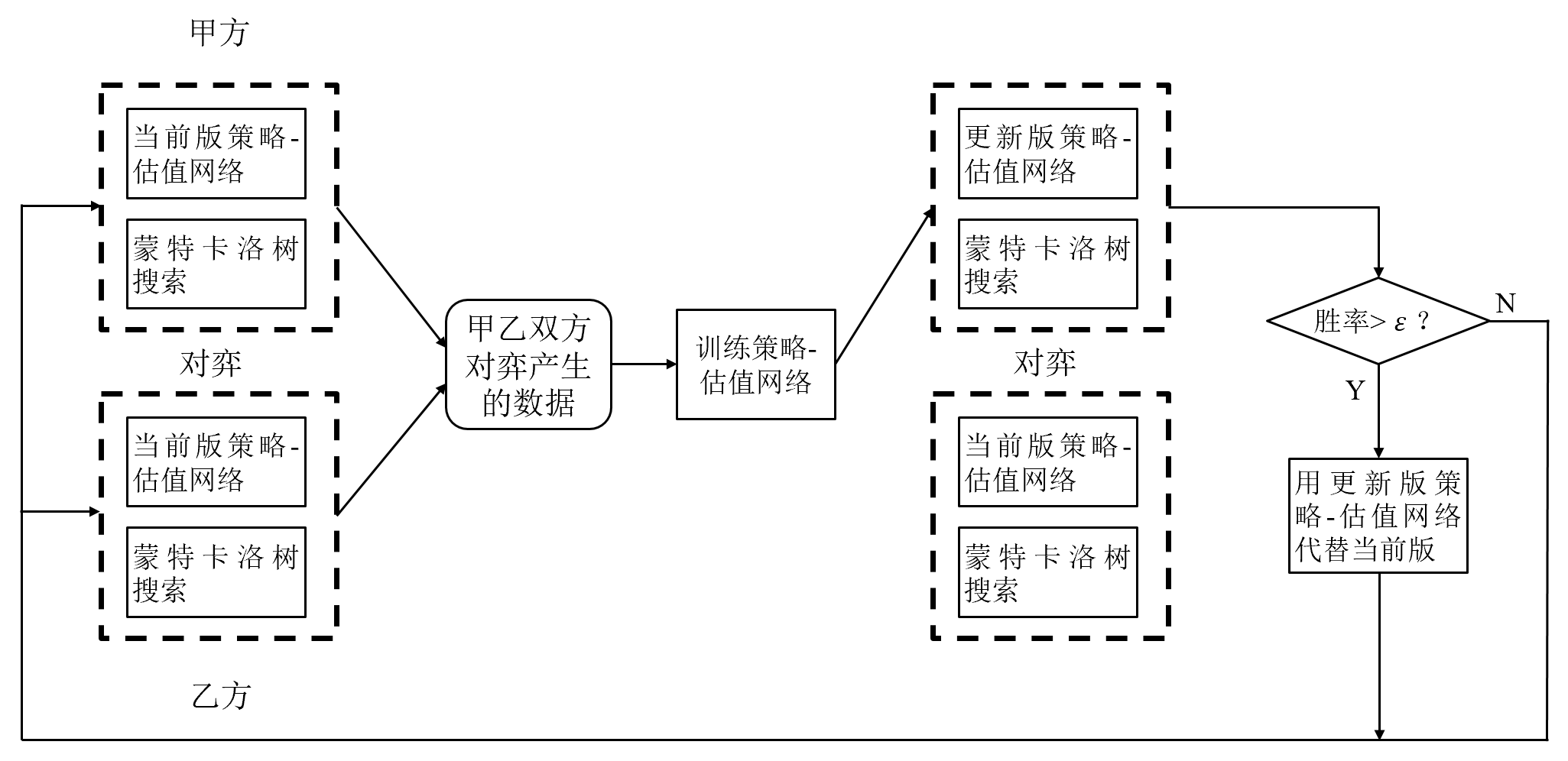
损失函数为:
其中为胜负值,为估值网络输出,为MCTS给出的该走法概率,为策略网络给出的该走法概率
引入多样性
人为引入噪声,增加策略网络输出的随机性,通常增加一个狄利克雷分布,生成一些大多值为0,小部分值较大的随机变量,并修正策略网络输出为: